
Le choix du moyen de stockage de données peut être décisif sur les performances d’une application. Entre HDFS, Apache Kudu et Amazon S3, les avantages varient et les inconvénients aussi.
Hadoop HDFS permet une forte évolutivité en termes de stockage pour un très faible coût, tandis qu’Apache Kudu se révèle plus performant sur l’analyse de données en temps-réel et les modifications sur des données stockées. On pensera aussi au stockage sur le cloud pour optimiser les charges de stockage sur Kudu et HDFS. Il est possible cependant de profiter des avantages des deux options tout en étant transparent avec les utilisateurs.
Cet article décrit une technique appelé le Sliding Window ou fenêtre glissante, consistant à utiliser Apache Impala pour traiter les données stockées aussi bien dans Kudu, HDFS que Amazon S3. Après une présentation des systèmes de fichiers et des technologies employées, nous aborderons le pattern en question ainsi qu’un exemple d’implémentation.
Comment fonctionnent Kudu, HDFS et S3 dans le cadre du Sliding Window
Kudu est conçu pour des analyses performantes sur des ensembles de données modifiables. Il fonctionne sur la base d’insertions et de modifications (insert/update) ainsi que des scans de colonnes pour permettre de multiples requêtes d’analyse en temps réel sur une même couche de données. Kudu excelle donc pour stocker des données immédiatement interrogeables et pour sa capacité à modifier et à supprimer des lignes de données en temps réel, permettant ainsi des corrections rapides sur les jeux de données concernés.
HDFS est conçu pour stocker de la donnée massivement et à un très faible coût. Il excelle sur des cas d’usage de données traitées par lots, partitionnées par colonne ou combinaison de colonnes. Combinée avec le format de fichier Apache Parquet, la donnée une fois structurée et partitionnée peut être accessible très rapidement et efficacement via Impala, tout en gardant une haute résilience grâce à la réplication (de facteur 3 par défaut).
Pour finir, Amazon S3 est un système de stockage objet dans le cloud. Il permet l’accès aux données, à distance.
Il est possible aujourd’hui de créer des tables Impala directement sur S3. Les requêtes effectuées sur les données seront légèrement moins performantes que sur HDFS avec le format Parquet, mais plus coûteuses par ailleurs notamment en terme d’utilisation réseaux. S3 sera suffisant pour stocker des données “froides”, anciennes ou des données que l’on souhaite consulter occasionnellement. Plus d’informations concernant Impala avec S3.
Pour des cas d’usage où la donnée est de faible granularité et modifiable, il sera judicieux de tout stocker sur Kudu pour pouvoir effectuer des requêtes pointilleuses ou des modifications à ligne de code prêt. En revanche, pour des cas d’usage où la donnée est potentiellement massive, on préfèrera utiliser HDFS Parquet. De plus, il est possible de stocker les données plus anciennes dans un bucket S3 via une autre table (archivage, traitement occasionnel). Si le cas d’usage nécessite les deux solutions de stockage, voire les trois, alors le Sliding Window pattern sera une solution des plus utiles.
Comment mettre en place un pattern Sliding Window
La première étape pour mettre en place ce pattern est de créer sur Impala des tables Kudu, HDFS Parquet et S3, qui ont la même structure. Une fois ces tables créées, il faut ensuite construire une vue qui permette de lire toutes ces tables. Une clause SQL “WHERE” sera utilisée pour définir une frontière qui sépare les données Kudu et HDFS, ainsi qu’une autre frontière entre les données HDFS et S3.
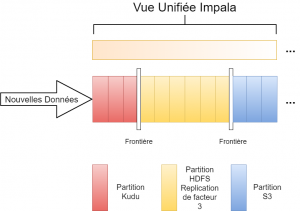
Cela permet aussi de déplacer les données entre les trois tables sans montrer les lignes doublons dans la vue. Une fois la donnée déplacée, on utilise la requête ALTER VIEW pour déplacer les frontières de la vue.
Ce pattern produit donc une fenêtre de temps coulissante (sliding window) dans laquelle des données fraîches sont stockées sur une table Kudu. Les données plus anciennes sont stockées sur une table HDFS et les données froides seront stockées dans S3. Utiliser Impala pour remonter des données depuis Kudu, HDFS et S3 permet de profiter des avantages des trois systèmes de stockage, en même temps.
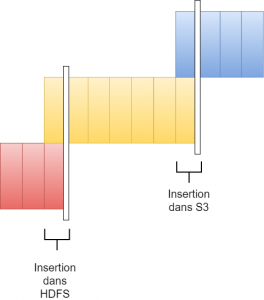
Le processus de déplacement de données entre Kudu et HDFS et entre HDFS et S3 se divise en deux phases. La première phase est celle de la migration de données et la seconde celle du changement de la métadonnée. Ce processus doit être planifié pour être exécuté régulièrement à l’aide de Cron, Apache Oozie ou tout autre outil d’orchestration.
Dans la première phase, la partition la plus ancienne de Kudu est copiée sur HDFS en tant que partition la plus récente de HDFS. Même si la donnée est répliquée entre ces deux tables, la frontière définie dans la vue va empêcher l’affichage des doublons. Il en va de même entre HDFS et S3. La partition la plus ancienne de HDFS sera migrée dans S3.
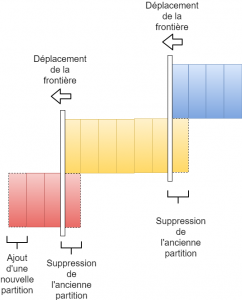
Dans la seconde phase, on ajoute une nouvelle partition dans Kudu, on réplique ensuite la partition Kudu la plus ancienne dans HDFS, cette partition devient alors la partition la plus récente dans HDFS. On supprime ensuite la partition Kudu répliquée. Enfin, entre HDFS et S3, ce processus restera la même.
Exemple d’implémentation d’un pattern Sliding Window
Dans cet exemple, nous allons implémenter un pattern Sliding Window. Il faut compter un délai de 3 mois pendant lequel les données peuvent être modifiées. Ensuite, ces données sont déplacées dans la table HDFS. Dans cette section, nous traitons du cas Kudu – HDFS, bien que le cas HDFS – S3 soit très similaire.
Création de la table Kudu
Cette table contiendra l’équivalent de trois mois de données modifiables. Il est important de bien partitionner la table car les suppressions de partitions via la clause Impala « DROP » sont plus performantes que les suppressions de données via la clause Impala « DELETE ». Il faut ensuite au sein de cette table définir une clé primaire (PRIMARY KEY). Cela peut être un attribut ou une combinaison d’attributs de la table et est nécessaire pour que toute la donnée ne soit pas écrite sur une seule partition.
Plus d’information sur l’utilisation d’Apache Impala avec Kudu.
Voici un exemple de table Kudu :
CREATE TABLE my_table_kudu
(
name STRING,
time TIMESTAMP,
message STRING,
PRIMARY KEY(name, time)
)
PARTITION BY
HASH(name) PARTITIONS 4,
RANGE(time) (
PARTITION ‘2018-01-01’ <= VALUES < ‘2018-02-01’, –Janvier
PARTITION ‘2018-02-01’ <= VALUES < ‘2018-03-01’, –Février
PARTITION ‘2018-03-01’ <= VALUES < ‘2018-04-01’, –Mars
PARTITION ‘2018-04-01’ <= VALUES < ‘2018-05-01’ –Avril
)
STORED AS KUDU;
Il y a aussi une partition supplémentaire correspondant à un mois (ici Avril) qui fait office de (marge d’un mois de données) pour que la donnée soit déplacée dans la table immutable HDFS.
Création de la table HDFS
Cette table aura la même structure que la table Kudu, à savoir qu’elle contiendra des données en masse, difficilement modifiables et antérieures à trois mois. La table sera aussi partitionnée par année, mois et jour pour une accessibilité des données plus efficace.
CREATE TABLE my_table_parquet
(
name STRING,
time TIMESTAMP,
message STRING
)
PARTITIONED BY (year int, month int, day int)
STORED AS PARQUET;
Création de la vue unifiée
La vue qui va unifier les trois tables est créée avec des UNION ALL de trois requêtes, de type SELECT. Nous devons expliciter les colonnes à afficher pour ne pas compter les colonnes de partitions uniques à la table HDFS. La clause WHERE et AND (pour HDFS) permet de définir la frontière entre Kudu et HDFS. Cela garantit que des données doublons ne soient pas lues.
A noter que l’on utilise le mot-clé UNION ALL et non UNION car ce dernier est l’équivalent de UNION DISTINCT, ce qui peut avoir un impact de performance important.
Les processus de maintenance
Maintenant que les tables et la vue ont été créées, nous allons créer des scripts pour maintenir le sliding window. Ces scripts peuvent être planifiés pour qu’ils puissent tourner de façon régulière.
Nous allons créer le script window_data_move.sql pour déplacer les vieilles données sur HDFS.
INSERT INTO ${var:hdfs_table} PARTITION (year, month, day)
SELECT *, year(time), month(time), day(time)
FROM ${var:kudu_table}
WHERE time >= add_months(« ${var:new_boundary_time} », -1)
AND time < « ${var:new_boundary_time} »;
COMPUTE INCREMENTAL STATS ${var:hdfs_table};
Le COMPUTE INCREMENTAL STATS n’est pas nécessaire, mais cela permet d’optimiser les requêtes Impala.
Pour lancer le script, nous utilisons Impala Shell en renseignant les variables:
impala-shell -i <impalad:port> -f window_data_move.sql
–var=kudu_table=my_table_kudu
–var=hdfs_table=my_table_parquet
–var=new_boundary_time= »2018-02-01″
Ensuite, nous allons créer un script sur lequel nous déplaçons la frontière vers l’avant en altérant la vue. Il s’agira d’utiliser la commande ALTER VIEW en donnant la nouvelle frontière de temps en argument.
Pour finir, nous créons le script window_partition_shift.sql pour effectuer l’ajout de la nouvelle partition ainsi que la suppression de la plus ancienne dans Kudu.
ALTER TABLE ${var:kudu_table}
ADD RANGE PARTITION add_months(« ${var:new_boundary_time} »,
${var:window_length}) <= VALUES < add_months(« ${var:new_boundary_time} »,
${var:window_length} + 1);
ALTER TABLE ${var:kudu_table}
DROP RANGE PARTITION add_months(« ${var:new_boundary_time} », -1)
<= VALUES < « ${var:new_boundary_time} »;
Pour exécuter ce script, nous passons par Impala-shell en passant les variables nécessaires.
impala-shell -i <impalad:port> -f window_partition_shift.sql
–var=kudu_table=my_table_kudu
–var=new_boundary_time= »2018-02-01″
–var=window_length=3.
Il faudra ensuite créer des scripts similaires pour déplacer les autres frontières de temps et les données à déplacer.
Le pattern du Sliding Window nécessite que certaines étapes soient effectuées à la chaîne. Il est alors judicieux d’automatiser ces étapes et de les planifier. Notre exemple d’implémentation a pour but d’aider à comprendre d’un angle plus technique ce pattern bien que ce ne soit pas la seule manière de l’implémenter.
Pour finir, il n’est pas nécessaire d’utiliser tous les systèmes de stockage présentés pour appliquer le Sliding Window, l’enjeu est de les définir en fonction du besoin exprimé.
Est-ce que le temps réel est un critère demandé ? Combien de téraoctets de données doit-on garder ? Préfère-t-on un accès très rapide ou un chargement de données pour un coût moindre ? HDFS peut-être la solution. Est-ce qu’on souhaite archiver les données très anciennes ou les requêter occasionnellement sans pour autant charger les disques avec la réplication de HDFS ? Dans ce cas S3 pourrait répondre à ce besoin.
Une fois ces besoins bien clarifiés, il est alors plus simple de déterminer si le Sliding Window s’avère utile au final.
Page Linkedin Cyrès
![]()