
Article mis à jour le 16/01/2018.
Si le terme Big Data est apparu à la fin des années 2000, l’explosion du nombre de données disponibles continue de progresser.
IBM estime que 90% des données disponibles (dont l’open data) dans le monde ont été créées ces deux dernières années. De nombreuses études estiment que le volume global de ces données va doubler chaque année.
Là où le concept de Big Data prend tout son sens, c’est qu’il n’est pas qu’un concept technique.
Les technologies Big Data permettent d’aller plus loin car il est possible depuis l’analyse de gros volumes de données, d’en extraire de nouvelles valeurs et informations inédites. En d’autres termes, au lieu d’analyser des données pour y chercher des corrélations qui valident l’une ou l’autre de nos intuitions, les technologies Big Data arriveront d’elles-même à extraire de l’ensemble des données des corrélations inédites.
Par exemple : en 2009, au plus fort de la crise de la grippe H1N1, les autorités sanitaires américaines ont demandé à Google de les aider à endiguer l’épidémie. Le logiciel de recherche a pu extraire des modèles précis de corrélation entre des termes recherchés et l’avancée de l’épidémie : un modèle d’analyse prédictive, quasi temps réel, a ainsi été mis en place.
L’open data, quand à lui, va avoir un rôle important comme indicateur de données sur la santé. Un arrêté du 19 juillet 2013 élargit les conditions d’accès et d’utilisation du SNIIRAM, la base de données de l’Assurance Maladie.
D’après les informations rendues disponibles par l’Assurance Maladie, la base traite 1,2 milliard de feuilles de soins chaque année et constitue l’une des plus grosses bases de données Open Data mondiales.
Deux chercheurs de l’école de médecine de Harvard, David McIver et John Brownstein, ont récemment démontré qu’on pouvait « se servir des requêtes menées sur les pages Wikipédia pour prédire avec précision, en temps réel, l’apparition des épidémies de grippe aux Etats-Unis ».
Âge, sexe, lieu de résidence, pathologie traitée, médicament prescrit, motif, durée de l’hospitalisation : toutes ses données misent en corrélation pourraient dresser un dossier médical complet d’un patient et plus encore. En croisant les données, il sera possible de mettre en lumière des pathologies liées à des médicaments (cf. l’affaire du médiator), à des modes de vie (le combat d’Erin Brockovich) ou encore à des situations de santé identifiées et localisées géographiquement.
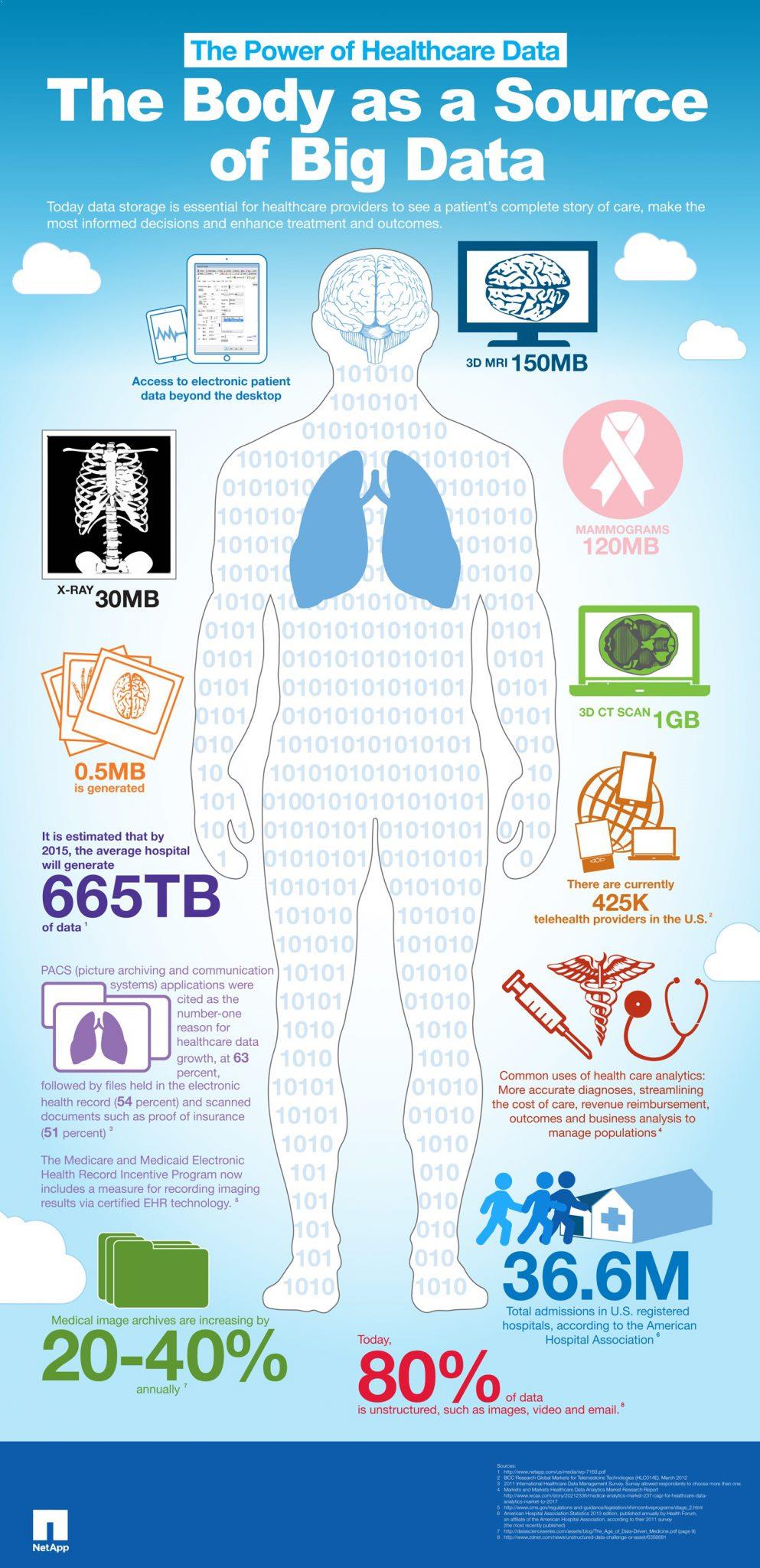
Vous retrouverez au travers de l’infographie suivante réalisée par NetApp des données chiffrées révélant en quoi le corps humain et les examens médicaux auxquels il est parfois soumis, peuvent être sources de nouvelles informations afin de servir la recherche et le progrès médical. L’exploitation des données big data et de l’open data servira sans doute demain à sauver des vies.
Page Linkedin Cyrès
![]()