
Introduction
Que vos bases de données contiennent des données sensibles liées au bancaire, à la santé, aux données personnelles d’utilisateurs ou que vous ayez simplement à cœur de mettre en place une bonne gouvernance des données, vous allez sans doute devoir anonymiser vos données. Le data masking est une pratique qui peut être difficile à mettre en place quand on n’a pas les bons outils.
Avec sa nouvelle plateforme CDP et plus précisément SDX, Cloudera offre plusieurs possibilités pour simplifier la data governance dans vos environnements. Aujourd’hui, nous allons vous présenter une de ces possibilités grâce à un exemple très simple de data masking via Ranger. Si vous ne savez pas ce qu’est CDP ou si vous voulez une présentation de ses fonctionnalités, n’hésitez pas à aller voir notre article sur le blog Cyres : La Cloudera Data Platform va plaire, mais à quel prix ?
Gouvernance des données
Avant toute chose, nous allons essayer de vous présenter la data governance. Ce terme peut sembler un peu générique et englobe en réalité une grande variété de concepts. Le site lebigdata.fr lui donne la définition suivante :
« La Data governance ou gouvernances des données en français correspond à l’ensemble des organisations et des procédures mises en place au sein d’une entreprise afin d’encadrer la collecte de données et leur utilisation. »
La gouvernance des données regroupe donc aussi bien l’accès aux données que ce que l’on en fait. On peut donc au moins reconnaitre dans ce terme les solutions d’autorisation d’accès aux données et les solutions d’audit de données. Afin de faire le lien avec l’introduction de notre article, voyons ce que Cloudera nous propose dans SDX (ou Shared Data Experience) qui pourrait coller à cette définition.
Cloudera SDX
Cloudera SDX est présenté par Cloudera comme une solution multi environnement de sécurité et de gouvernance des données dans les écosystèmes Cloudera. Cette partie de CDP englobe en particulier 3 solutions qui vont nous intéresser dans cet article :
- Atlas
- Ranger
- Data Catalog
Atlas
Apache Atlas est une solution proposant aux entreprises de la gestion des metadatas et de la gouvernance afin de leur permettre de construire des catalogues de leurs données ainsi que de classer et de les organiser pour fournir des outils collaboratifs aux data scientists, analysts et aux équipes de data governance. Si on reprend la séparation de la gouvernance des données vue précédemment, Atlas se place comme une solution d’audit qui rentre entièrement dans ce concept.
Ranger
Apache Ranger est une solution permettant d’autoriser, de monitorer et de gérer l’accès et la sécurité des données au sein d’un environnement Hadoop. Si on reprend une fois de plus la séparation de la gouvernance des données vue précédemment, Ranger intervient dans l’autorisation d’accès aux données.
Data Catalog
Cloudera Data Catalog est une solution propriétaire permettant de comprendre, sécuriser et gouverner ses données dans des environnements Cloud hybrides. Cette solution se présente clairement comme une solution de data governance et rentre donc dans le sujet de cet article. Avec ces trois solutions, Cloudera SDX se positionne donc bien comme une solution de gouvernance des données. Afin de ne pas rendre cet article plus long que nécessaire, nous n’allons explorer qu’une seule de ces trois solutions (et un seul cas d’utilisation) : Le data masking dans Apache Ranger.
Le data masking avec Apache Ranger
Pour notre exemple, nous allons utiliser une table « employee_metadata_exported » représentant les informations des employés d’une entreprise et contenant les colonnes suivantes :
- factory_id
- employee_id
- gender
- occupation
- birthdate
- salary
Notre but va être de masquer l’email des employés à un de nos rôles. Pour cela, nous allons utiliser deux utilisateurs :
- su.llebail un utilisateur du groupe data_scientist_group et associé au rôle data_scientist_role
- llebail un utilisateur du groupe administration_group et associé au rôle administration_role
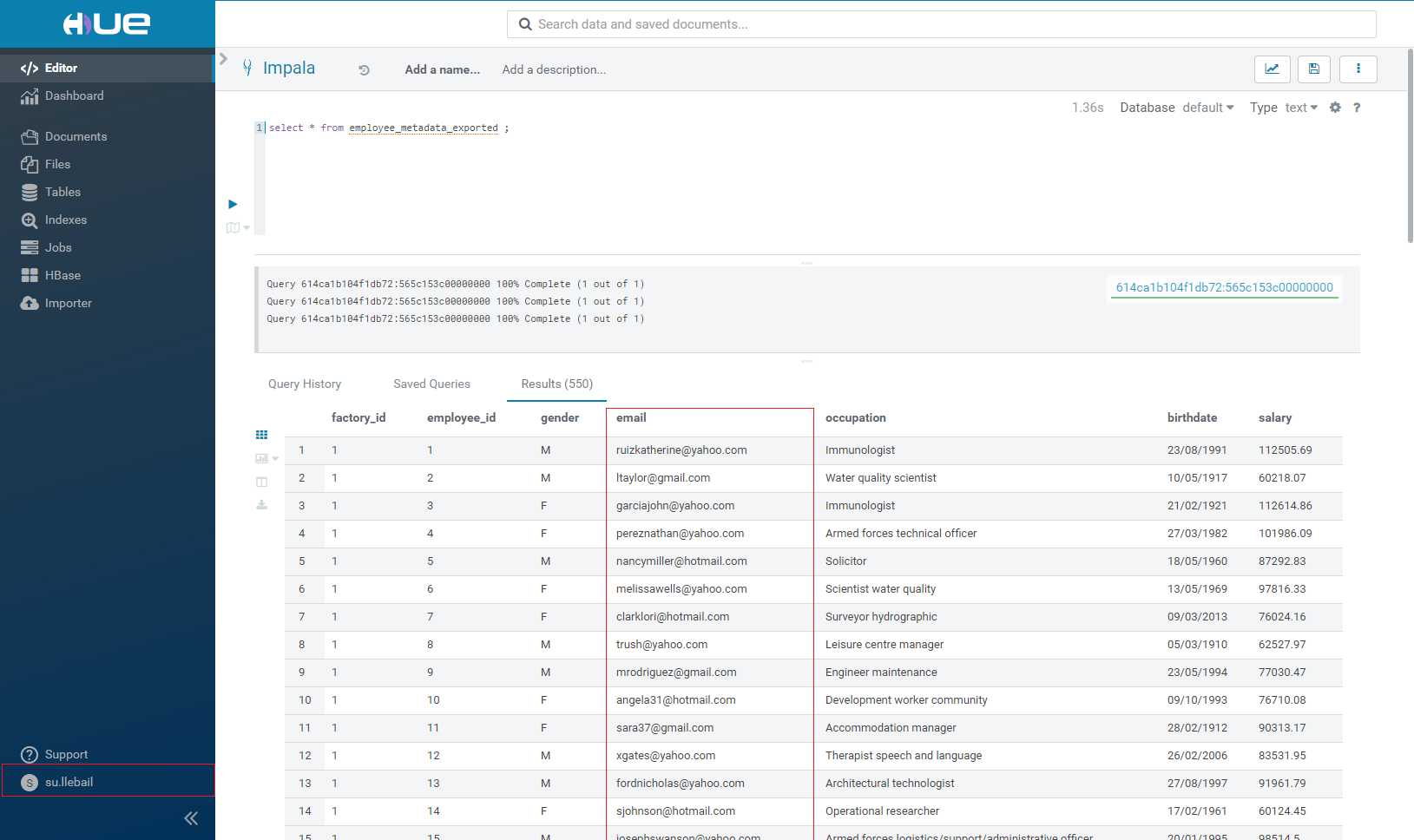
Comme nous pouvons le voir ci-dessous, l’utilisateur su.llebail peut voir l’email de chacun des employés de la table employee_metadata_exported. Aucun data masking n’ayant été effectué sur cette table pour l’instant, tous les utilisateurs des rôles ayant accès à cette table peuvent avoir accès à ces email.
Notre but dans cet exemple va être de masquer l’email des employés au rôle data_scientist_role et de conserver l’accès à cette information au rôle administration_role.
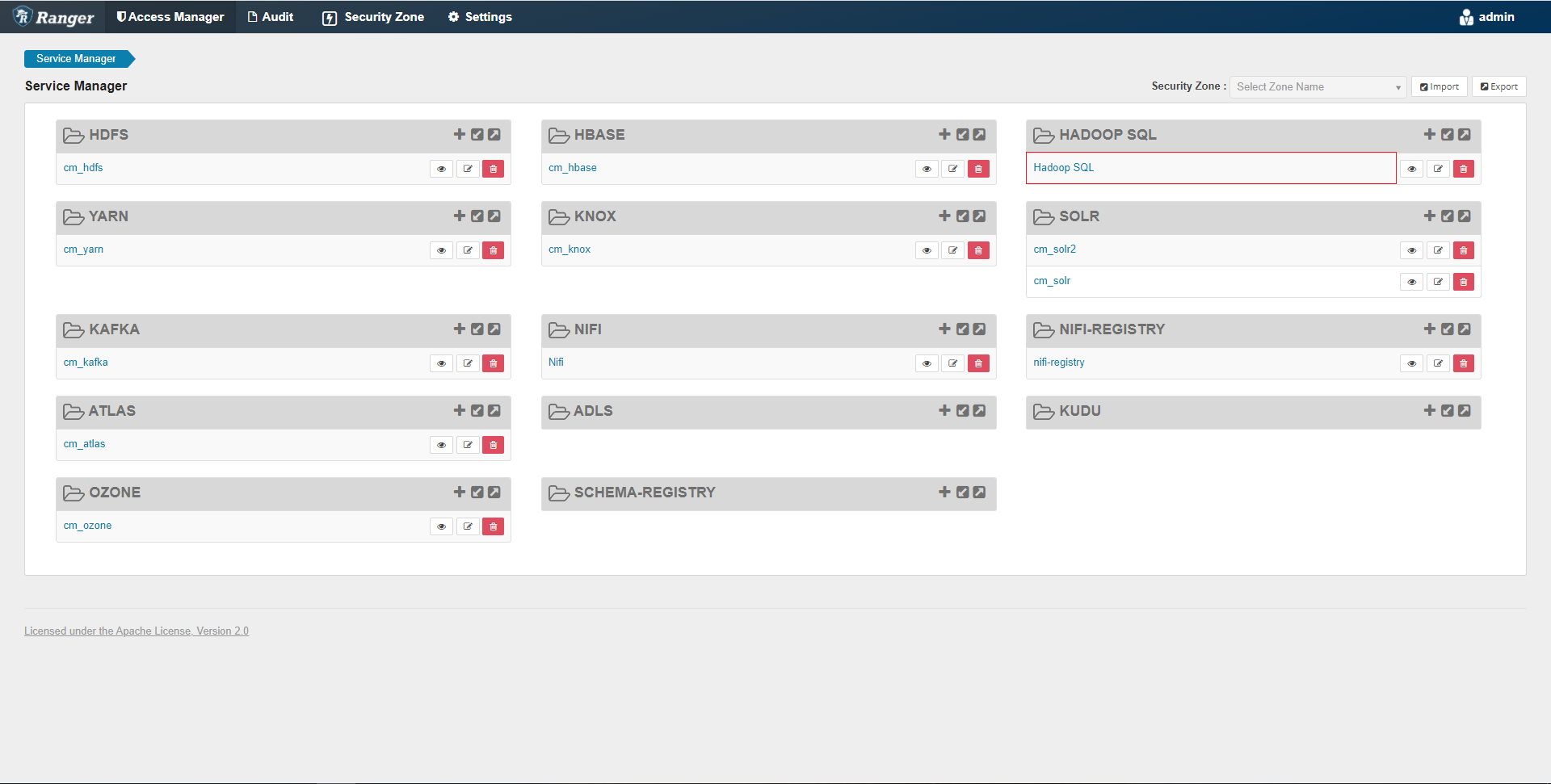
Pour effectuer ce data masking, nous allons nous rendre sur la web UI de Ranger dans les « ressources based policies ». Sur cette page, nous avons une vue d’ensemble des services dont les policies sont gérées par Ranger dans notre cluster. Pour notre exemple de data masking, nous allons aller dans les policies du service Hive. Pour cela, nous allons cliquer sur Hadoop SQL.
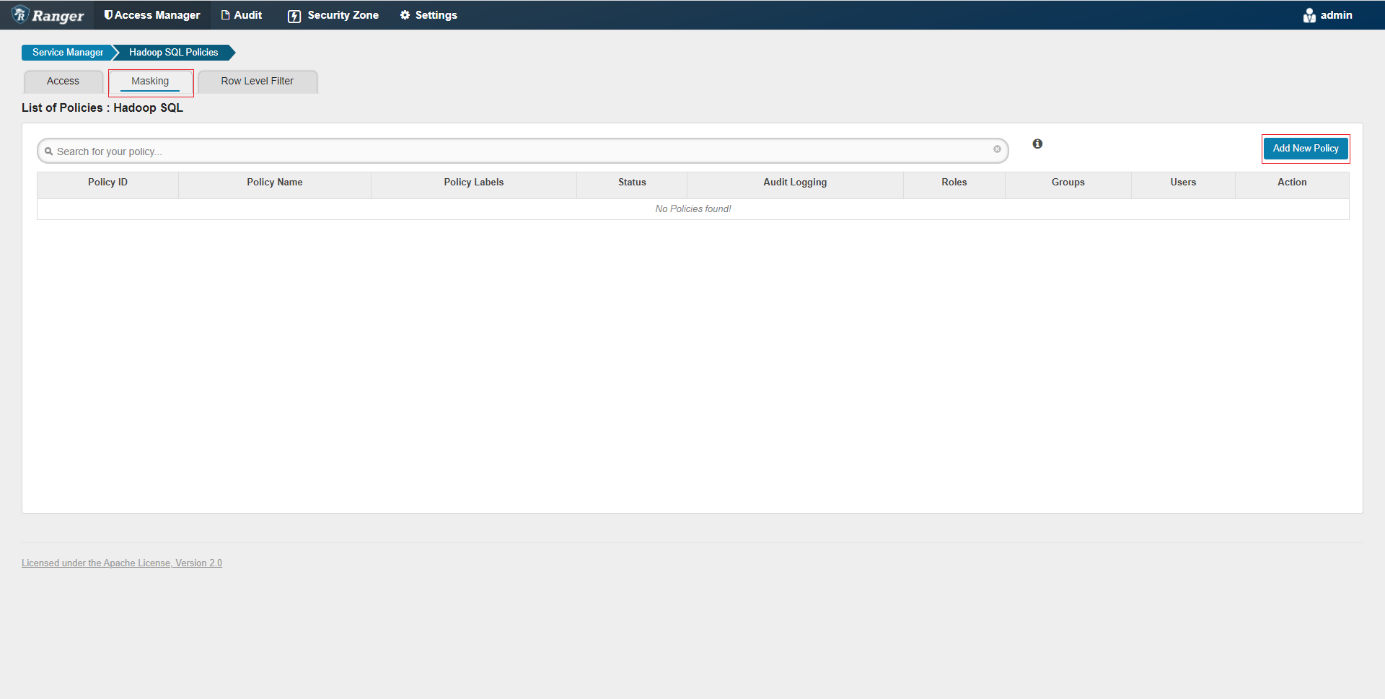
Une fois dans la page Hadoop SQL Policies qui regroupe les policies Hive, nous allons aller dans l’onglet Masking. Nous allons ensuite cliquer sur le bouton « Add New Policy » afin d’ajouter notre policy de data masking.
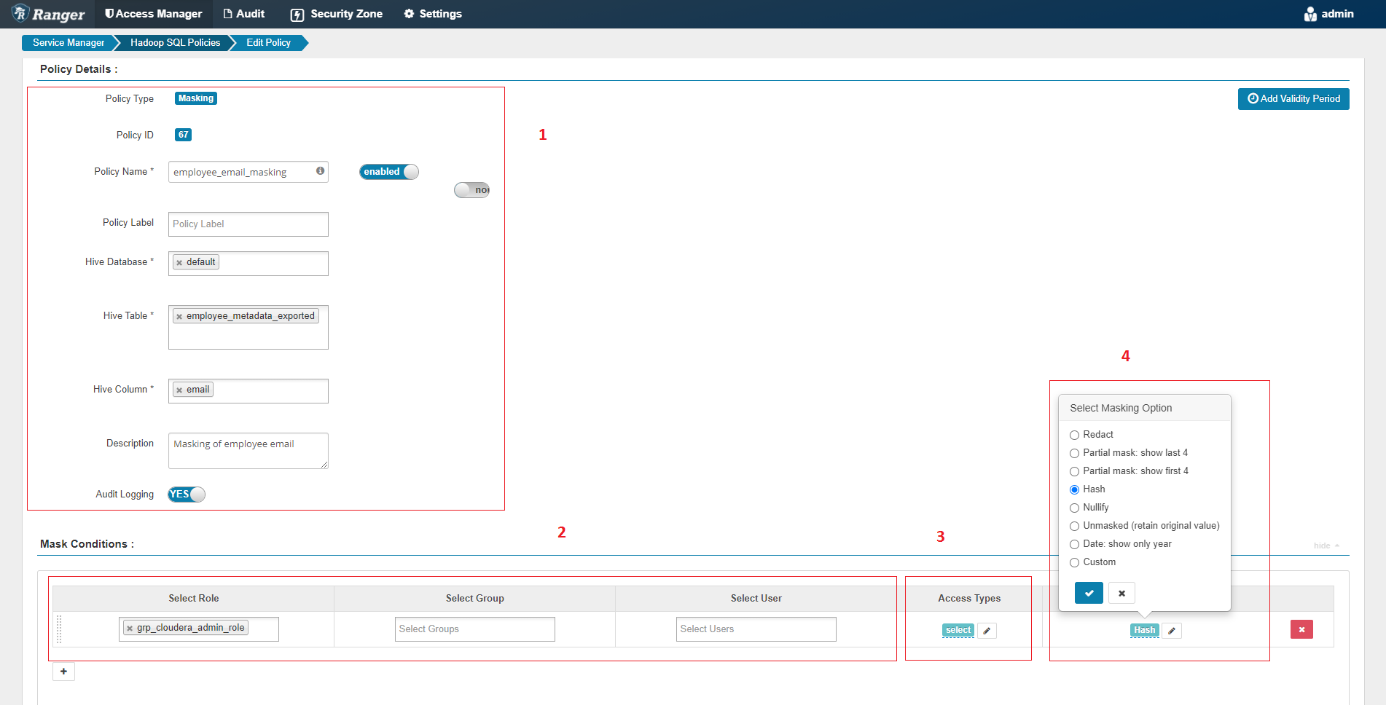
La page d’ajout de policy de data masking se présente comme sur la capture ci-dessous. Afin de faciliter les explications, nous pouvons la séparer en 4 parties.
Dans la partie 1 nous avons les informations liées à la policy :
- Policy Type : Le type de policy (masking dans notre cas)
- Policy ID : L’ID de la policy (cette information sert à retrouver dans les audits quelle est la policy qui a autorisé ou refusé une action)
- Policy Name : le nom que l’on donne à notre policy (nous avons appelé notre policy « employee_email_masking » mais il n’y a pas vraiment de contrainte pour ce champ donc on peut utiliser nos propres nomenclatures)
- Hive Database : La database sur laquelle notre policy va s’appliquer (dans notre cas c’est la base default)
- Hive Table : La table sur laquelle notre policy va s’appliquer (dans notre cas, c’est la table employee_metadata_exported)
- Hive Column : La colonne de la table sur laquelle la policy va s’appliquer (dans notre cas email car c’est la valeur que nous voulons masquer)
- Description : Une description de la policy
Dans la partie 2, nous avons les informations liées aux utilisateurs, groupes ou rôles concernés par la policy. Afin de ne pas rencontrer de soucis lors de suppression d’utilisateurs ou de groupes, il est recommandé de privilégier l’utilisation des rôles. On peut cependant avoir à renseigner des utilisateurs dans le cas de policies d’accès pour des services accounts par exemple.
Dans la partie 3, nous avons l’access type pour préciser à quel type d’accès s’applique la policy. Dans notre cas, il s’agit de select.
Et dans la partie 4, nous avons l’option de Masking. Cette option représente par quel type de données seront remplacés les données que l’utilisateur ciblé par la policy ne pourra pas voir. Dans notre exemple, l’email sera remplacé par un Hash pour les utilisateurs associés au rôle data_scientist_role.
Une fois notre policy de data masking renseignée, nous pouvons vérifier avec la même requête que précédemment que l’email est bien masqué pour les utilisateurs associés au rôle data_scientist_role.
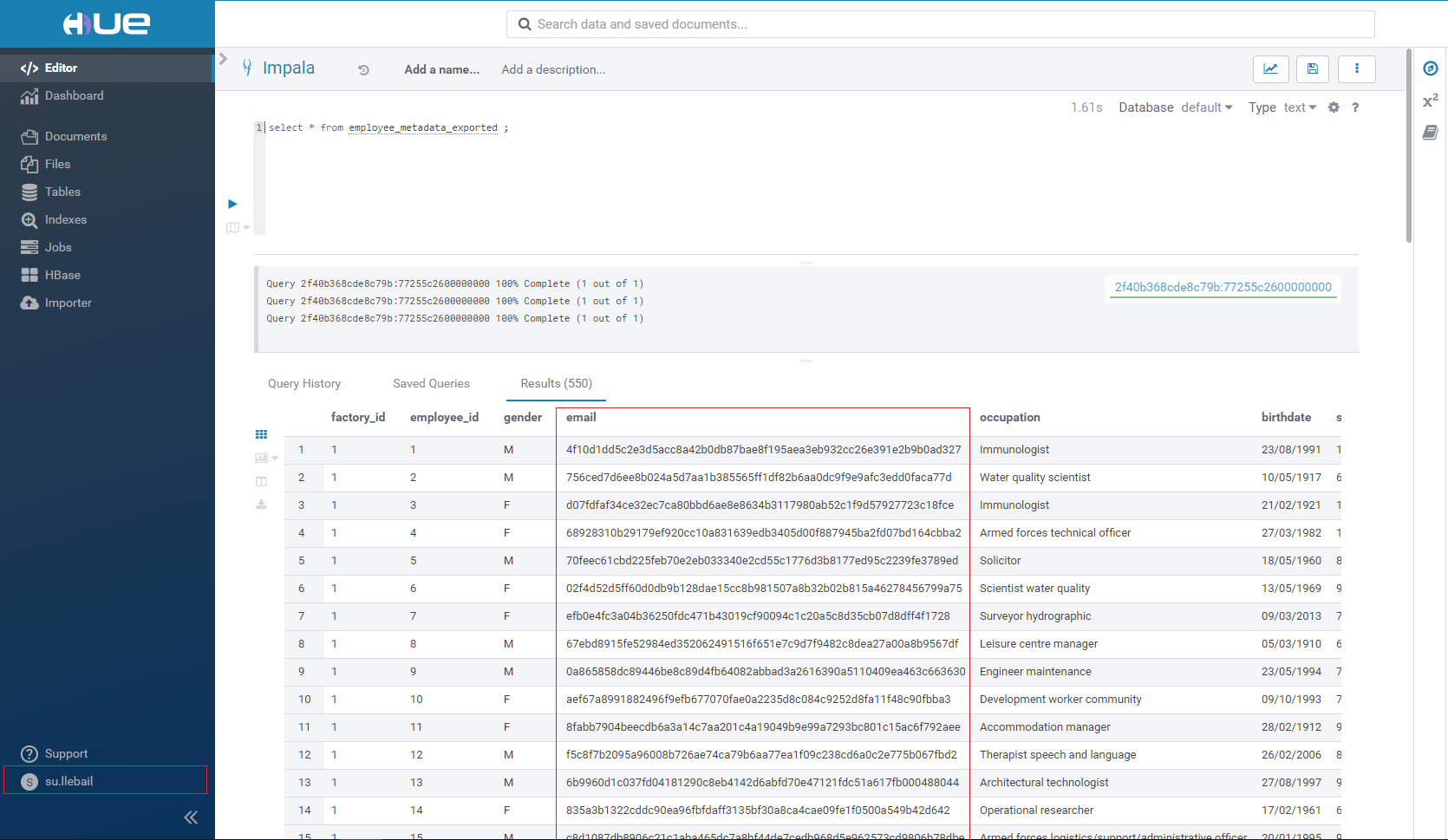
Et qu’elle ne s’applique pas aux utilisateurs du rôle administration_role.
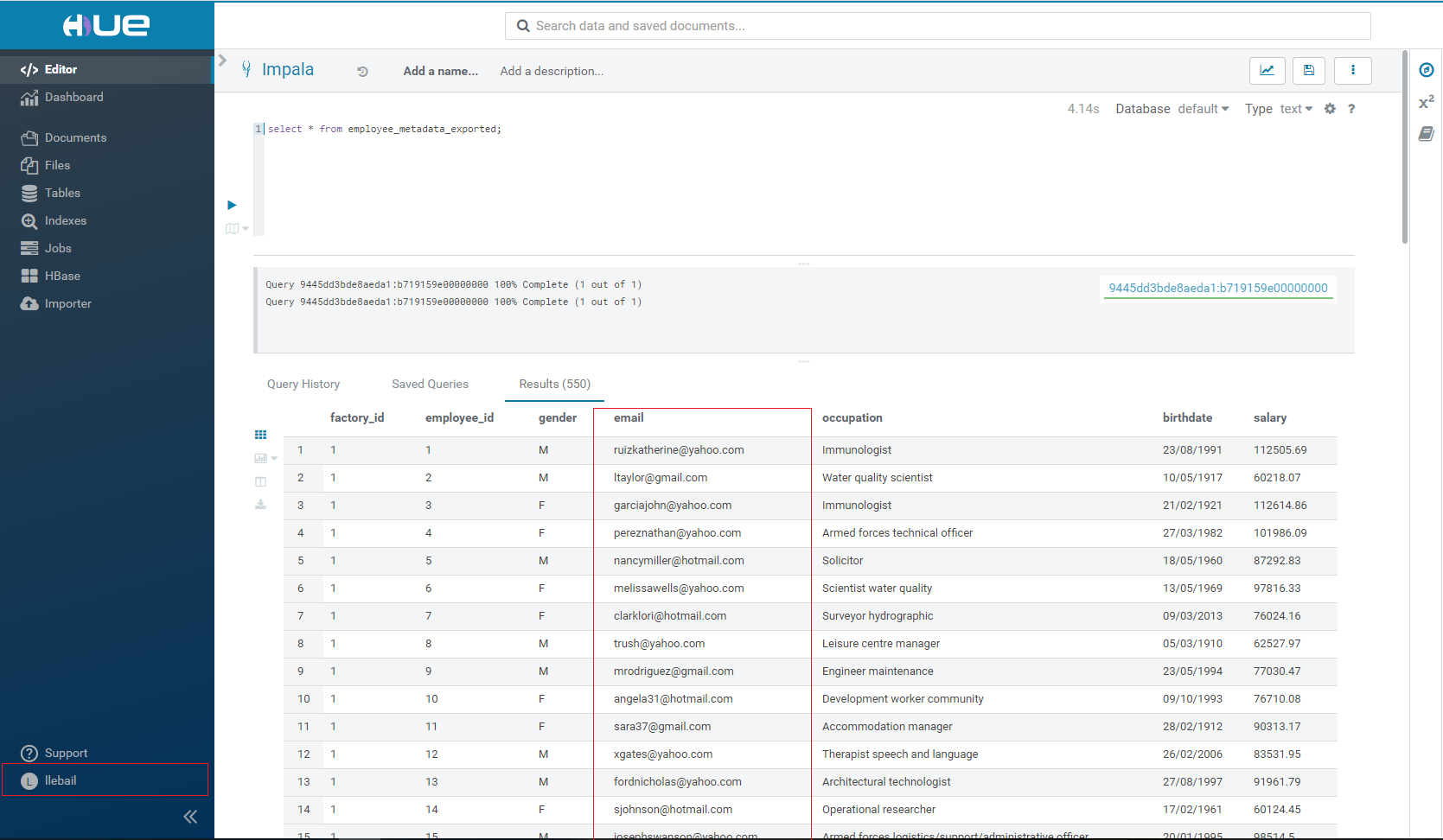
Voilà ! Ce n’est pas plus difficile que ça ! Bien sûr, il s’agit ici d’un exemple très simple. Dans un vrai cas d’utilisation, il est recommandé de prévoir des stratégies détaillées de data governance avec des granularités plus ou moins importantes de droits d’accès en fonction de la sensibilité de la donnée à masquer et de l’utilisation que vos différents rôles en font.
Que retenir en matière de gouvernance des données ?
Comme nous avons pu le voir dans cet article, la gouvernance des données est un concept très large qui nécessite d’avoir les bons outils. Dans ce but, Cloudera nous propose sa solution SDX afin de nous simplifier la tâche.
Aujourd’hui, nous avons vu comment Ranger rendait le data masking simple pour les entreprises, mais ce n’est qu’une partie des possibilités. Continuez à suivre nos articles pour voir quelles sont les autres possibilités de Ranger et à quels autres cas d’usages répond SDX !
Page Linkedin Cyrès
![]()