
Cloudera a depuis quelques mois sorti sa nouvelle plateforme Cloud native : Cloudera Data Platform. Elle se décline en plusieurs parties : de la gouvernance via SDX, une partie Cloud, piloté par Cloudera et déployable sur AWS et Azure (bientôt GCP) et enfin une partie hébergeable sur des serveurs chez soi avec une possibilité d’hybridation, possédant des capacités de déport de calcul dans un environnement conteneurisé Openshift.
Attention ! Les conteneurs sont à l’honneur pour ces offres attractives mais attention aux coûts cachés. Passons en revue ces différentes offres pour y voir plus clair
Shared Data Experience (SDX)
Une grosse nouveauté de la part de Cloudera dans cette nouvelle approche du Big Data réside dans la mise à disposition d’une couche de sécurité et de gouvernance de la donnée généralisée. Elle est centralisée pour l’ensemble du catalogue Cloudera Data Platform et offre de nouvelles perspectives en terme d’organisation, de gestion et de mise à disposition de la donnée. L’idée derrière cela est de permettre à ses clients de faire du multi cloud sans se soucier des biques sous-jacentes.
Développée et hébergée par Cloudera directement, elle est accessible aux personnes détentrices d’une licence, à l’url suivante : console.cdp.cloudera.com. On y trouve les briques principales de SDX :
- Management Console, console principale permettant l’administration de tous les services de CDP.
- Workload Manager, évolution de Workload XM, il permet l’analyse fine des traitements à des fins d’optimisation.
- Replication Manager, évolution de BDR pour Backup and Disaster Recovery, il permet la réplication entre environnements des données HDFS et Hive.
- Data Catalog, pilier central des données, il offre la possibilité de comprendre, gérer et sécuriser l’ensemble des données.
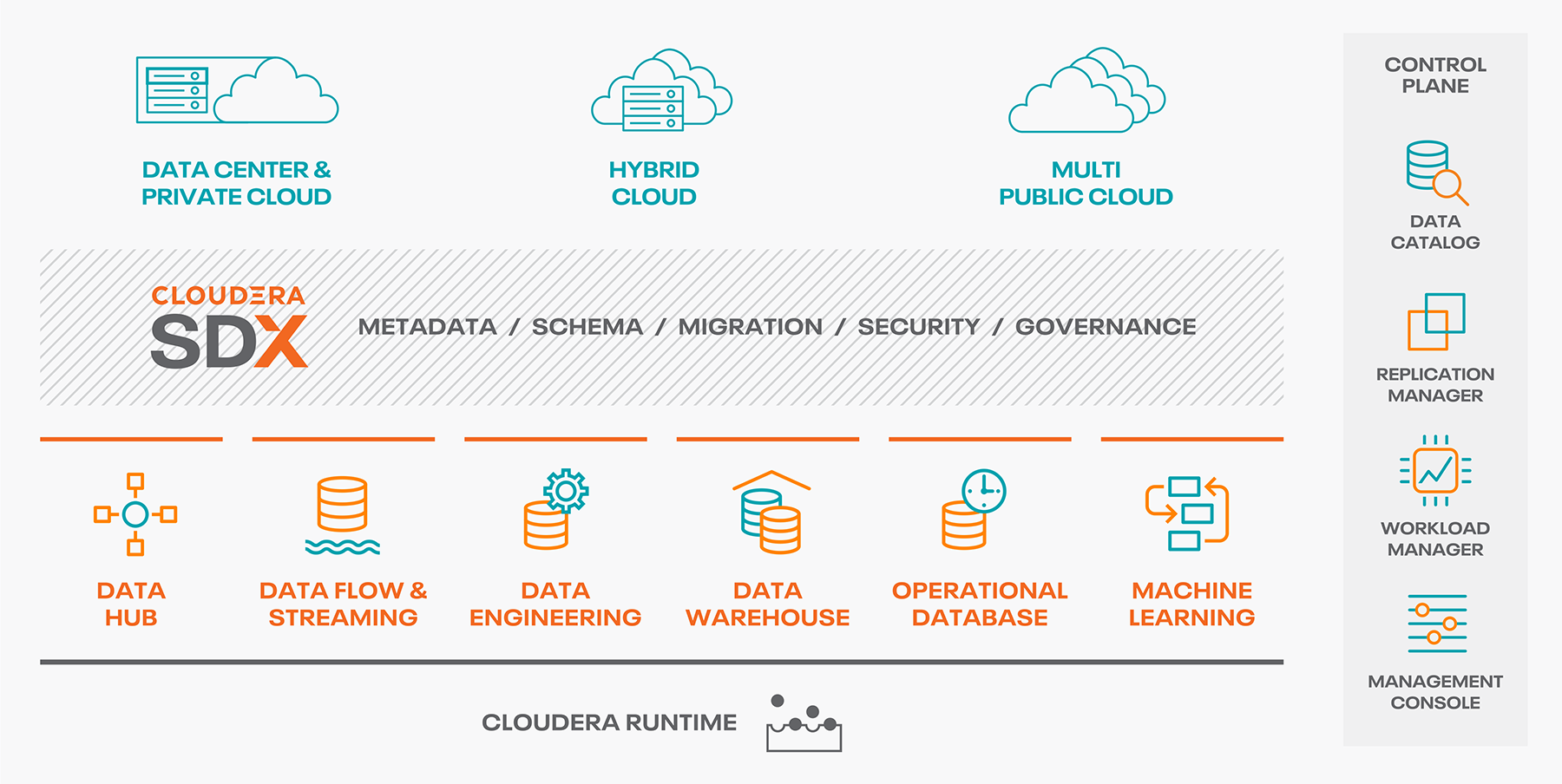
Cloudera Data Platform – Public Cloud
Cette partie d’offre se décline en plusieurs « expériences », qui répondent à des besoins différents, mais complémentaires. Pour lancer l’un de ses outils vous devrez d’abord créer un « environnement », qui correspond à un référentiel de Cloud public (ex. AWS ou Azure). Il embarque un cluster dit « datalake » ainsi que les briques nécessaires à l’authentification aux travers des plateformes.
Cloudera Data Hub Clusters
Il s’agit de cluster standard, similaire à un « datalake » comme on a pu avoir avec CDH, mais dans le cloud, cette offre embarque différents composants de l’écosystème Hadoop, en passant par un système de template préconfiguré par Cloudera. Il est possible de se créer ses propres templates pour une meilleure customisation.
Cloudera Data Engineering (CDE)
Récemment sortie, cette offre permet l’exécution de job Spark sur des environnements Kubernetes managés (par le cloud provider). Elle fournit un ensemble de fonctionnalités pour piloter ces jobs via des outils comme Airflow. Il est décomposé en plusieurs éléments :
- Le service CDE : un cluster Kubernetes en charge d’orchestrer les clusters virtuels
- Cluster virtuel : un cluster virtuel définis par des ressources sur demande
- Job : des traitements à exécuter sur cluster virtuel
- Ressource : Un ensemble de fichiers de dépendances pour les jobs (python, .jar, etc)
Cloudera utilise le framework Yunikorn pour la gestion des ressources on top of Kubernetes,
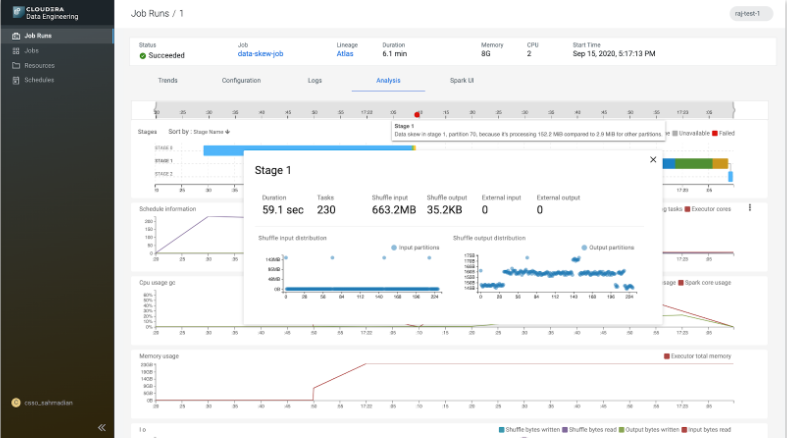
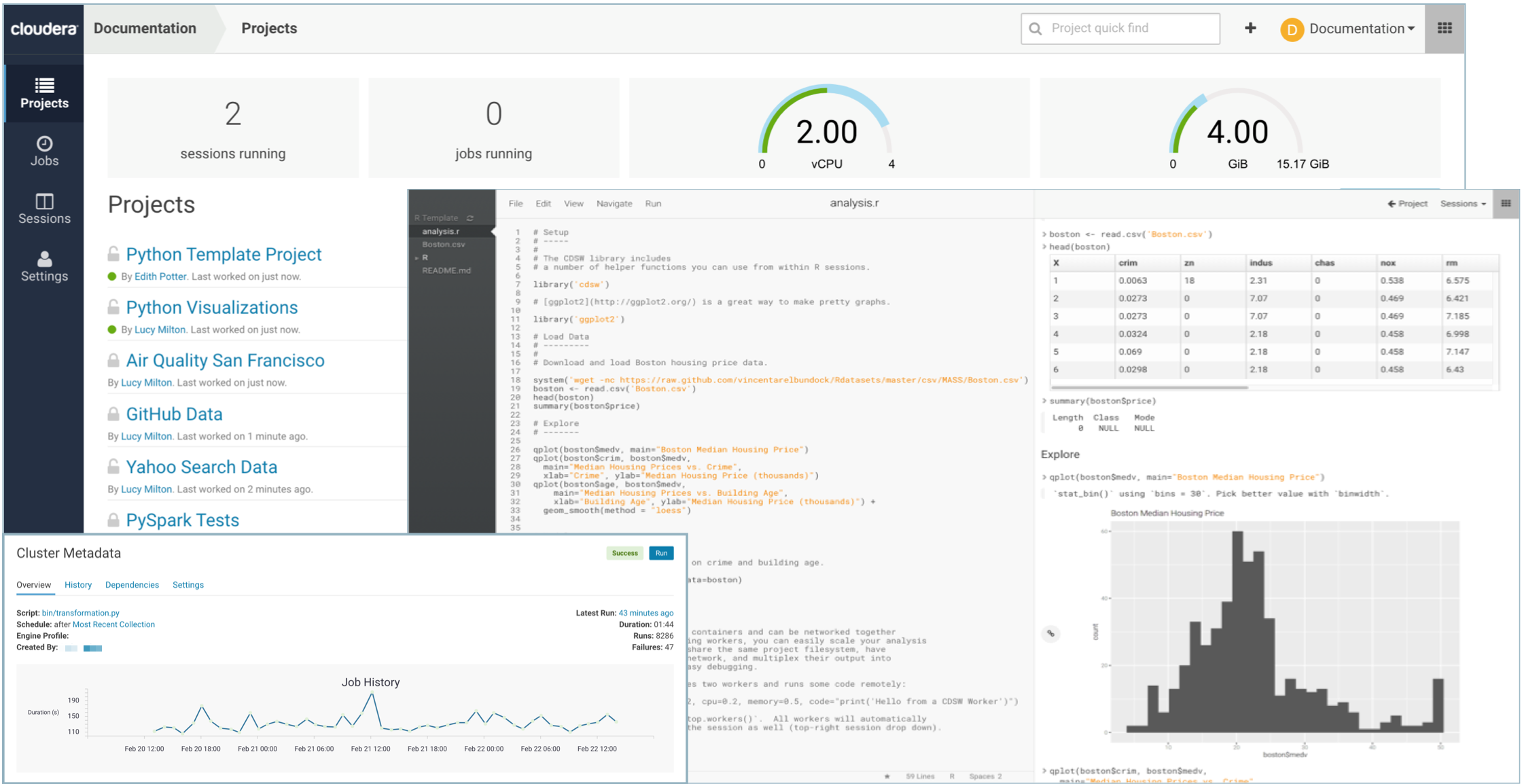
Cloudera Machine Learning (CML)
Evolution de Cloudera Data Science Workbench (CDSW), c’est l’une des expériences que nous estimons la plus prometteuse. Celle-ci embarque un panel de technologies et mécanismes pour la Data Science et le Machine Learning pour permettre du MLOps. Voici un résumé de ces fonctionnalités :
- Notebook individuel (Cloudera made ou Jupyter)
- Projet et possibilité de collaboration
- Gestion des modèles prédictifs (intégration à SDX pour la gouvernance de ces modèles)
- Exposition des modèles en mode API REST basé sur de la conteneurisation
- Possibilité de faire des expérimentations pour un même modèle avec plusieurs jeux de données
- Capacité de scheduler des traitements
- Client python permettant la distribution des traitements au travers de la plateforme CML
Cloudera travaille depuis le rachat de Arcadia Data à intégrer leur solution en tant qu’outil de Data Visualisation principal de l’écosystème de la Cloudera Data Platform. Il sera possible depuis plusieurs expériences Cloudera, d’utiliser cet outil de visualisation.
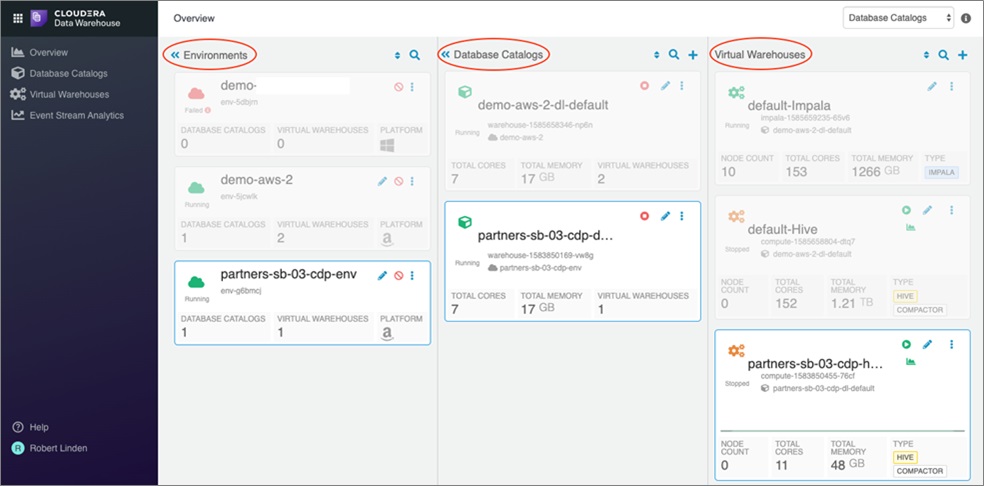
Cloudera Data Warehouse (CDW)
Outil self-service à destination des analystes, il repose sur :
- Des Catalogues de données virtuels. Ils utilisent le stockage du « datalake » de l’environnement ou du stockage objet extérieur.
- Des Data Warehouses virtuels. Un ensemble de ressource de calcul prêt à traiter des requêtes analytiques sur les jeux de données.
Voici un résumé des fonctionnalités principales :
- Gestion des catalogues de données indépendamment du stockage
- Scaling des entrepôts via la conteneurisation sous-jacente
- Possibilité de mettre en pause les warehouse pour économiser les coûts d’utilisation
- Data Warehouse Hive ou Impala
- Interactions SQL via HUE ou DAS
Cloudera Operational Database (COD)
Petite dernière des expériences Cloudera, elle permet à la fois du temps réel et de l’analyse de données. Cette offre donne accès à HBase, Phoenix, Spark, Kafka, Knox et Zookeeper entre autres, directement managés sur du Kubernetes. Voici les composants et ainsi que leurs implications :
- Phoenix permet du SQL par-dessus HBase
- HBase, base NoSQL orienté colonne très scalable
- Zookeeper pour le quorum des différents services
- Knox gateway pour gérer les accès et permettre un point d’accès centralisé
- HDFS pour stocker les fichiers WALs d’HBase
- AWS S3 ou ADLS Gen2 pour stocker les HFiles HBase
- SDX pour gérer la sécurité et la gouvernance
Cloudera Data Platform – Private Cloud
Anciennement CDP Data Center (DC) et fraîchement renommé CDP Private Cloud, c’est l’équivalent de CDH, mais avec l’intégration d’outils venant d’Hortonworks comme Atlas et Ranger, ou bien Hive on Tez et Hive LLAP.
Cette offre permet à ceux qui possèdent déjà une infrastructure Cloudera ou Horton, de migrer vers la nouvelle solution. Au moment de la rédaction de cet article, l’outil de migration CDH 6/HDP 3 vers CDP n’est pas encore disponible, celui pour CDH 5/HDP 2 l’est cependant.
Installable uniquement si vous possédez une licence, le modèle de facturation évolue. Auparavant on avait des licences par serveur, maintenant on observe une tarification au serveur avec des limitations pour les ressources : il faut compter des frais pour chaque tranche de 1 cœur/8 Go de RAM supérieur à 16 cœurs/128 Go de RAM (https://fr.cloudera.com/products/pricing.html).
Cloudera propose avec cette offre, un système de « contexte de donnée« . Cela permet de spécifier des services (HDFS, Ranger, Atlas) comme référentiel pour d’autre cluster dit « de compute ». Cela laisse penser à une utilisation similaire à la partie SDX disponible dans le Cloud, mais directement on premise.
Un lien entre votre plateforme interne et la partie Cloud est possible. Cela permet, d’après Cloudera, de pouvoir déporter du calcul dans le Cloud pour décharger la plateforme interne. À suivre, car cela permettrait de transférer des jobs Spark sans avoir à recréer soit même un environnement dans le Cloud.
Cloudera ne s’arrête pas là ! La conteneurisation peut aussi venir à vous si vous ne souhaitez pas mettre vos traitements dans le Cloud. Ils proposent l’intégration des expériences CDP directement on premise, en rajoutant à votre infrastructure un environnement conteneurisé. À ce jour seul Openshift est supporté pour déployer les différentes offres Cloudera attenante à votre datalake.
Conclusion
Après quelques mois, à découvrir, tester, manipuler et opérer sur CDP, nous avons pu déceler des avantages mais aussi des inconvénients. La partie Public Cloud est prometteuse et regorge de possibilités comme la flexibilité du provisoning, l’ensemble des versions accessibles, la kerberisation automatique des infrastructures ou encore la sécurité centralisée. La majeure partie des fonctionnalités intéresseraient bon nombre d’entreprise. L’intégration d’outils venant d’Hortonworks tel que Ranger et Atlas est un vrai plus pour la gouvernance d’environnement Big Data. Cloudera pousse un éventail d’outils assez large dans la plateforme, dans l’optique d’augmenter le nombre de possibilités et de cas d’usage avec ses outils.
Un point vient noircir le tableau : le tarif. Pour déployer une expérience de Machine Learning, il faut compter un environnement CDP avec un datalake, un cluster Kubernetes managé et un ensemble d’instance qui reçoivent les traitements. Cela implique donc un coût minimal et non compressible. Cela nécessite que le ROI sur les développements Big Data soit connu, maitrisé et important.
La partie Private Cloud aussi a évolué pour permettre l’intégration d’outils plus efficace. Mais là encore, le système de tarification avec du surcoût pour les ressources fait grimper la note annuelle. D’autant que pour acquérir les expériences chez soi, il faut une infrastructure Openshift et tous ce qui va avec…
Malgré ces points la plateforme Cloudera se dote d’une capacité Cloud agnostic et hybrid non négligeable pour des entreprises qui cherchent à proposer des standards à leurs équipes. Leader sur la gestion de la donnée, Cloudera sait se réinventer pour conquérir de nouveaux marchés.
Page Linkedin Cyrès
![]()